6.1.1. bedops¶
bedops is a core tool for finding relationships between two or more genomic datasets.
This is an important category of problems to solve. As examples, one might want to:
- Know how much overlap exists between the elements of two datasets, to quantitatively establish the degree to which they are similar.
- Merge or filter elements. For example, retrieving non-overlapping, “unique” elements from multiple BED files.
- Split elements from multiple BED files into disjoint subsets.
The bedops program offers several Boolean set and multiset operations, including union, subset, and difference, to assist investigators with answering these types of questions.
Importantly, bedops handles any number of any-size inputs at once when computing results in order to maximize efficiency. This use case has serious practical consequences for many genomic studies.
One can also use bedops to symmetrically or asymmetrically pad coordinates.
6.1.1.1. Inputs and outputs¶
6.1.1.1.1. Input¶
The bedops program reads sorted BED data and BEDOPS Starch-formatted archives as input.
Finally, bedops requires specification of a set operation (and, optionally, may include modifier options).
Support for common headers (including UCSC track headers) is offered through the --header option. Headers are stripped from output.
6.1.1.2. Usage¶
The bedops program takes sorted BED-formatted data as input, either from a file or streamed from standard input. It will process any number of input files in parallel.
If your data are unsorted, use BEDOPS sort-bed to prepare data for bedops. You only need to sort once, as all BEDOPS tools read and write sorted BED data.
Because memory usage is very low, one can use sorted inputs of any size. Processing times generally follow a simple linear relationship with input sizes (e.g., as the input size doubles, the processing time doubles accordingly).
The --help option describes the set operation and other options available to the end user:
bedops
citation: http://bioinformatics.oxfordjournals.org/content/28/14/1919.abstract
version: 2.4.41 (typical)
authors: Shane Neph & Scott Kuehn
USAGE: bedops [process-flags] <operation> <File(s)>*
Every input file must be sorted per the sort-bed utility.
Each operation requires a minimum number of files as shown below.
There is no fixed maximum number of files that may be used.
Input files must have at least the first 3 columns of the BED specification.
The program accepts BED and Starch file formats.
May use '-' for a file to indicate reading from standard input (BED format only).
Process Flags:
--chrom <chromosome> Process data for given <chromosome> only.
--ec Error check input files (slower).
--header Accept headers (VCF, GFF, SAM, BED, WIG) in any input file.
--help Print this message and exit successfully.
--help-<operation> Detailed help on <operation>.
An example is --help-c or --help-complement
--range L:R Add 'L' bp to all start coordinates and 'R' bp to end
coordinates. Either value may be + or - to grow or
shrink regions. With the -e/-n operations, the first
(reference) file is not padded, unlike all other files.
--range S Pad or shink input file(s) coordinates symmetrically by S.
This is shorthand for: --range -S:S.
--version Print program information.
Operations: (choose one of)
-c, --complement [-L] File1 [File]*
-d, --difference ReferenceFile File2 [File]*
-e, --element-of [number% | number] ReferenceFile File2 [File]*
by default, -e 100% is used. 'bedops -e 1' is also popular.
-i, --intersect File1 File2 [File]*
-m, --merge File1 [File]*
-n, --not-element-of [number% | number] ReferenceFile File2 [File]*
by default, -n 100% is used. 'bedops -n 1' is also popular.
-p, --partition File1 [File]*
-s, --symmdiff File1 File2 [File]*
-u, --everything File1 [File]*
-w, --chop [bp] [--stagger [bp]] [-x] File1 [File]*
by default, -w 1 is used with no staggering.
Example: bedops --range 10 -u file1.bed
NOTE: Only operations -e|n|u preserve all columns (no flattening)
6.1.1.3. Operations¶
To demonstrate the various operations in bedops, we start with two simple datasets A and B, containing genomic elements on generic chromsome chrN:

These datasets can be sorted BED or Starch-formatted files or streams.
Note
The bedops tool can operate on two or more multiple inputs, but we show here the results of operations acting on just two or three sets, in order to help demonstrate the basic principles of applying set operations.
6.1.1.3.1. Everything (-u, –everything)¶
The --everything option is equivalent to concatenating and sorting BED elements from multiple files, but works much faster:
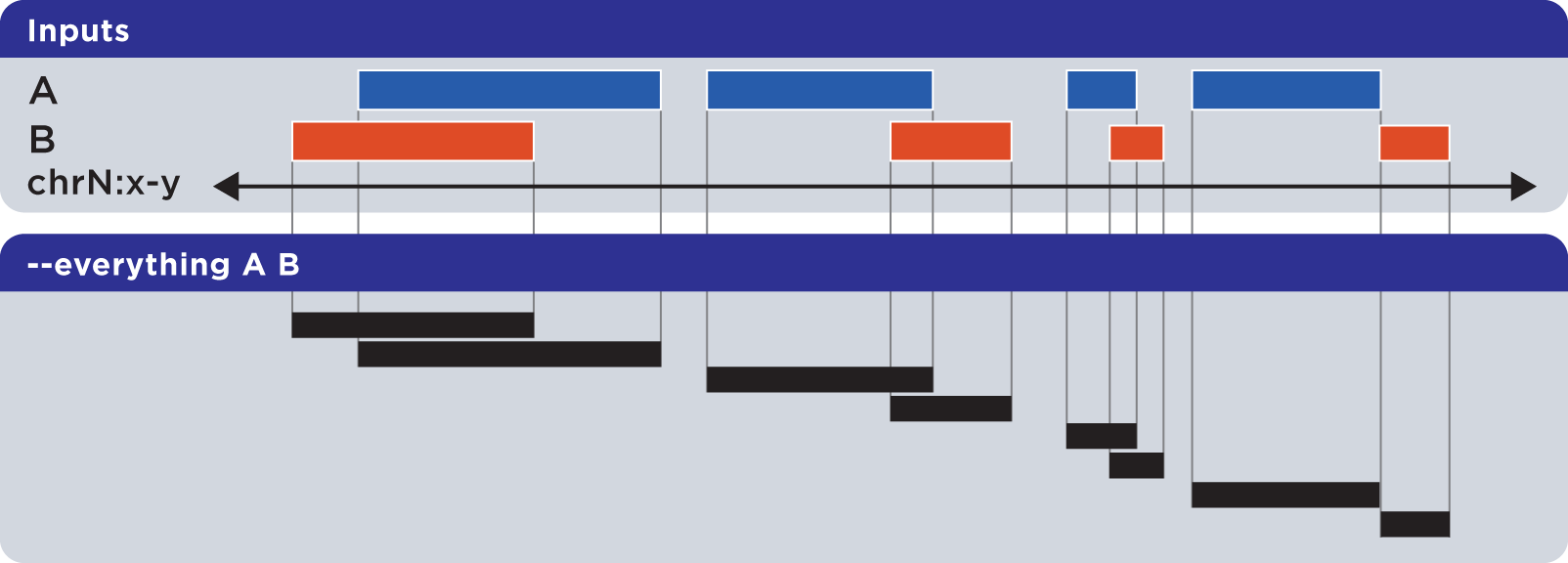
As with all BEDOPS tools and operations, the output of this operation is sorted.
Note
The --everything option preserves all columns from all inputs. This is useful for multiset unions of datasets with additional ID, score or other metadata.
Example
To demonstrate the use of --everything in performing a multiset union, we show three sorted sets First.bed, Second.bed and Third.bed and the result of their union with bedops:
$ more First.bed
chr1 100 200
chr2 150 300
chr2 200 250
chr3 100 150
$ more Second.bed
chr2 50 150
chr2 400 600
$ more Third.bed
chr3 150 350
$ bedops --everything First.bed Second.bed Third.bed > Result.bed
$ more Result.bed
chr1 100 200
chr2 50 150
chr2 150 300
chr2 200 250
chr2 400 600
chr3 100 150
chr3 150 350
This example uses three input sets, but you can specify two, four or even more sets with --everything to take their union.
6.1.1.3.2. Element-of (-e, –element-of)¶
The --element-of operation shows the elements of the first (”reference”) file that overlap elements in the second and subsequent “query” files by the specified length (in bases) or by percentage of length.
In the following example, we search for elements in the reference set A which overlap elements in query set B by at least one base:
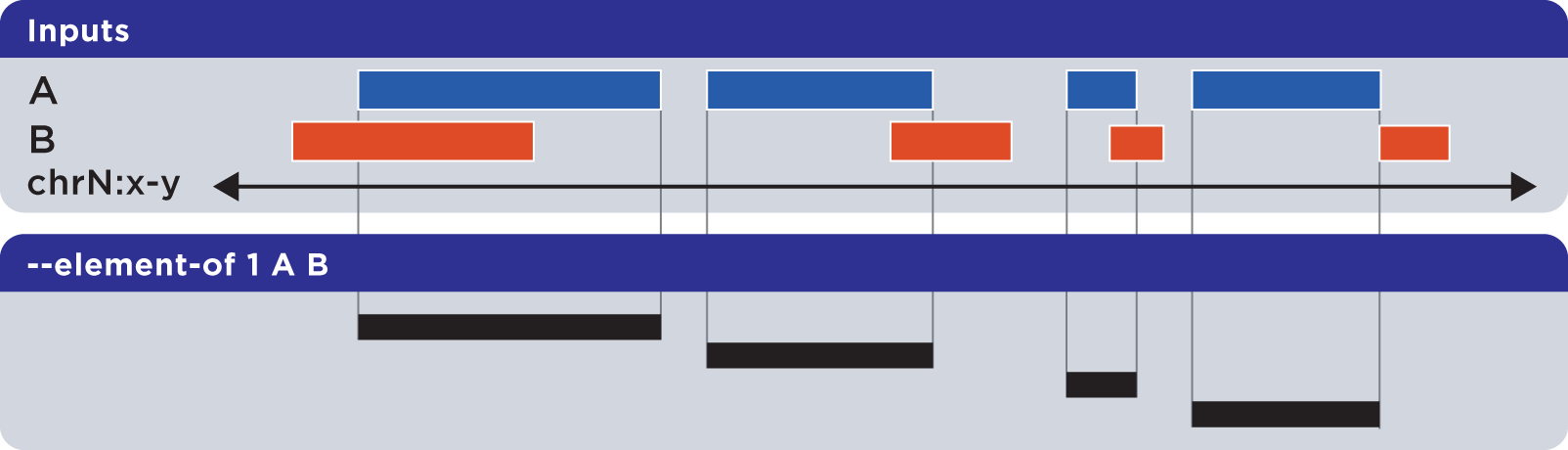
Elements that are returned are always from the reference set (in this case, set A).
Note
The --element-of option preserves all columns from the first (reference) input.
Example
The argument to --element-of is a value that species to degree of overlap for elements. The value is either integral for per-base overlap, or fractional for overlap measured by length.
Here is a demonstration of the use of --element-of 1 on two sorted sets First.bed and Second.bed, which looks for elements in the First set that overlap elements in the Second set by one or more bases:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --element-of 1 First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 200
chr1 150 160
chr1 400 475
One base is the least stringent (default) integral criterion. We can be more restrictive about our overlap requirement by increasing this value, say to 15 bases:
$ bedops --element-of 15 First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 200
Only this element from the First set overlaps one or more elements in the Second set by a total of fifteen or more bases.
We can also use percentage of overlap as our argument. Let’s say that we only want elements from the First set, which overlap half their length or more of a qualifying element in the Second set:
$ bedops --element-of 50% First.bed Second.bed > Result.bed
$ more Result.bed
chr1 150 160
Note that –element-of is not a symmetric operation, as demonstrated by reversing the order of the reference and query set:
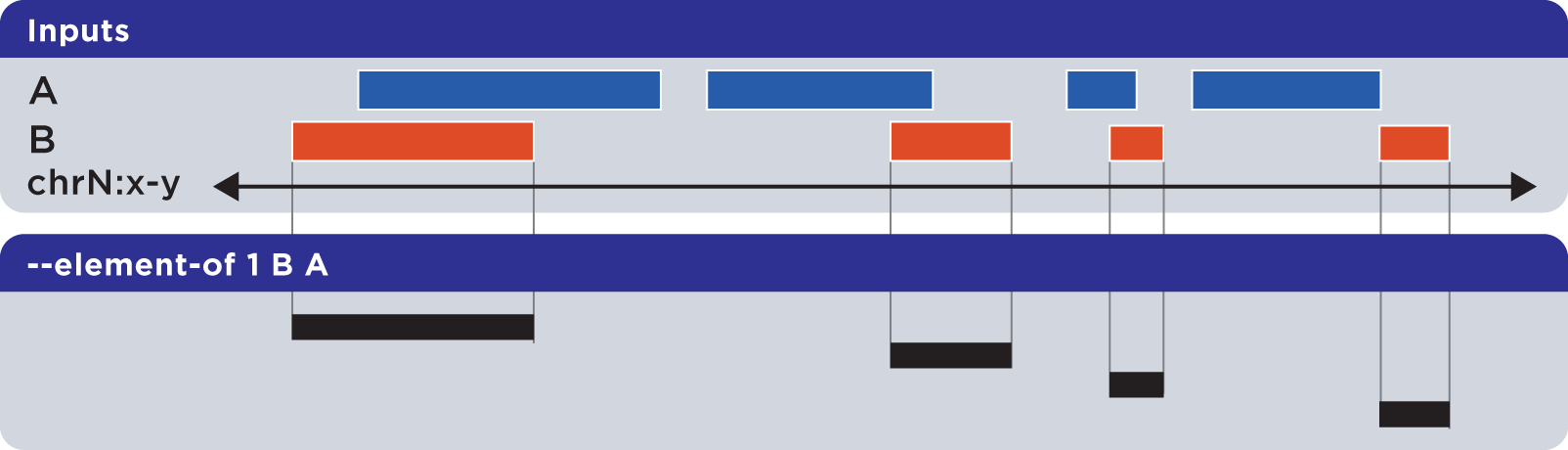
Example
As we show here, by inverting the usual order of our sample sets First and Second, we retrieve elements from the Second set:
$ bedops --element-of 1 Second.bed First.bed > Result.bed
$ more Result.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
While this operation is not symmetric with respect to ordering of input sets, --element-of (-e) does produce exactly everything that --not-element-of (-n) does not, given the same overlap criterion and ordered input sets.
Note
We show usage examples with two files, but --element-of supports three or more input sets. For a more in-depth discussion of --element-of and how overlaps are determined with three or more input files, please review the BEDOPS forum discussion on this subject.
6.1.1.3.3. Not-element-of (-n, –not-element-of)¶
The --not-element-of operation shows elements in the reference file which do not overlap elements in all other sets. For example:
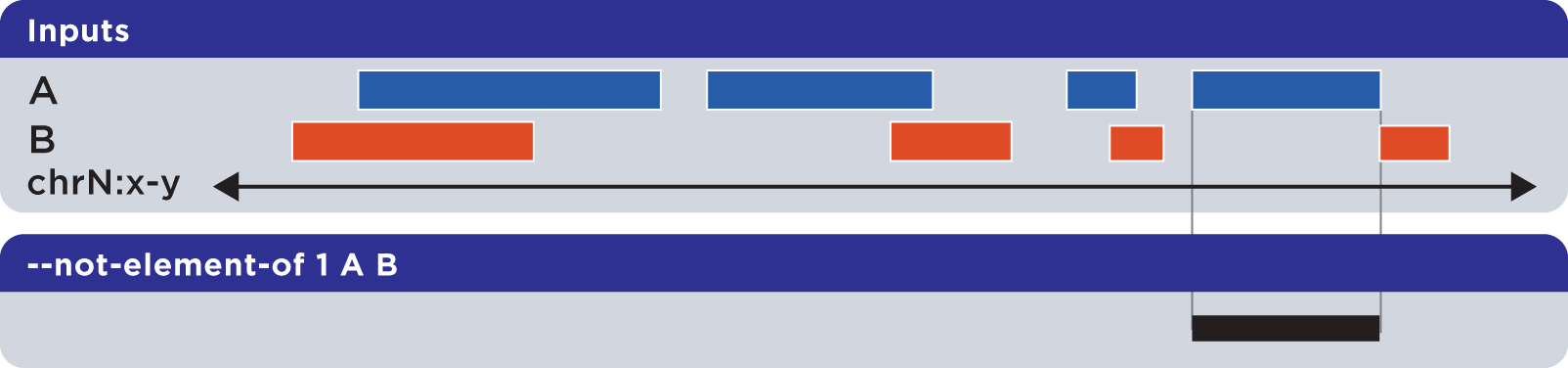
Example
We again use sorted sets First.bed and Second.bed to demonstrate --not-element-of, in order to look for elements in the First set that do not overlap elements in the Second set by one or more bases:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --not-element-of 1 First.bed Second.bed > Result.bed
$ more Result.bed
chr1 200 300
chr1 500 550
As with the --element-of (-e) operator, the overlap criterion for --not-element-of (-n) can be specified either by length in bases, or by percentage of length.
Similarly, this operation is not symmetric – the order of inputs will specify the reference set, and thus the elements in the result (if any).
Note
The --not-element-of operatior preserves columns from the first (reference) dataset.
Note
The same caveat applies to use of --not-element-of (-n) as with --element-of (-e), namely that the second and all subsequent input files are merged before the set operation is applied. Please review the BEDOPS forum discussion thread on this topic for more details.
6.1.1.3.4. Complement (-c, –complement)¶
The --complement operation calculates the genomic regions in the gaps between the contiguous per-chromosome ranges defined by one or more inputs. The following example shows the use of two inputs:
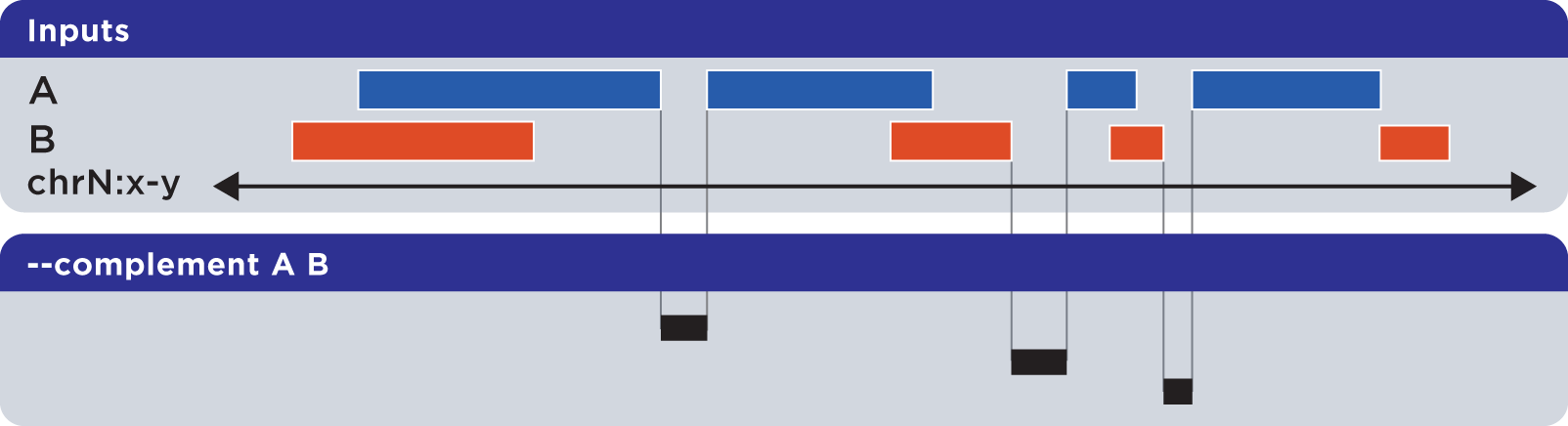
Note this computed result will lack ID, score and other columnar data other than the first three columns that contain positional data. That is, computed elements will not come from any of the input sets, but are new elements created from the input set space.
Example
To demonstrate --complement, we again use sorted sets First.bed and Second.bed, in order to compute the “gaps” between their inputs:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --complement First.bed Second.bed > Result.bed
$ more Result.bed
chr1 300 400
chr1 475 490
As we see here, for a given chromosome, gaps are computed between the leftmost and rightmost edges of elements in the union of elements across all input sets.
Note
For a more in-depth discussion on using --complement with left and right bounds of input chromosomes, please review the BEDOPS forum discussion on this subject.
6.1.1.3.5. Difference (-d, –difference)¶
The --difference operation calculates the genomic regions found within the first (reference) input file, excluding regions in all other input files:

Example
To demonstrate --difference, we use sorted sets First.bed and Second.bed and compute the genomic space in First that excludes (or “subtracts”) ranges from Second:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --difference First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 120
chr1 125 150
chr1 160 300
chr1 400 460
chr1 470 475
chr1 500 550
Note
As with --element-of and --not-element-of, this operation is not symmetric. While --not-element-of preserves all columns of elements found in the reference input and allows one to define overlaps, the --difference operator simply reports every genomic range as three-column BED, which does not overlap elements found in the second and subsequent input files by any amount.
6.1.1.3.6. Symmetric difference (-s, –symmdiff)¶
The --symmdiff operation calculates the genomic range that is exclusive to each input, excluding any ranges shared across inputs:
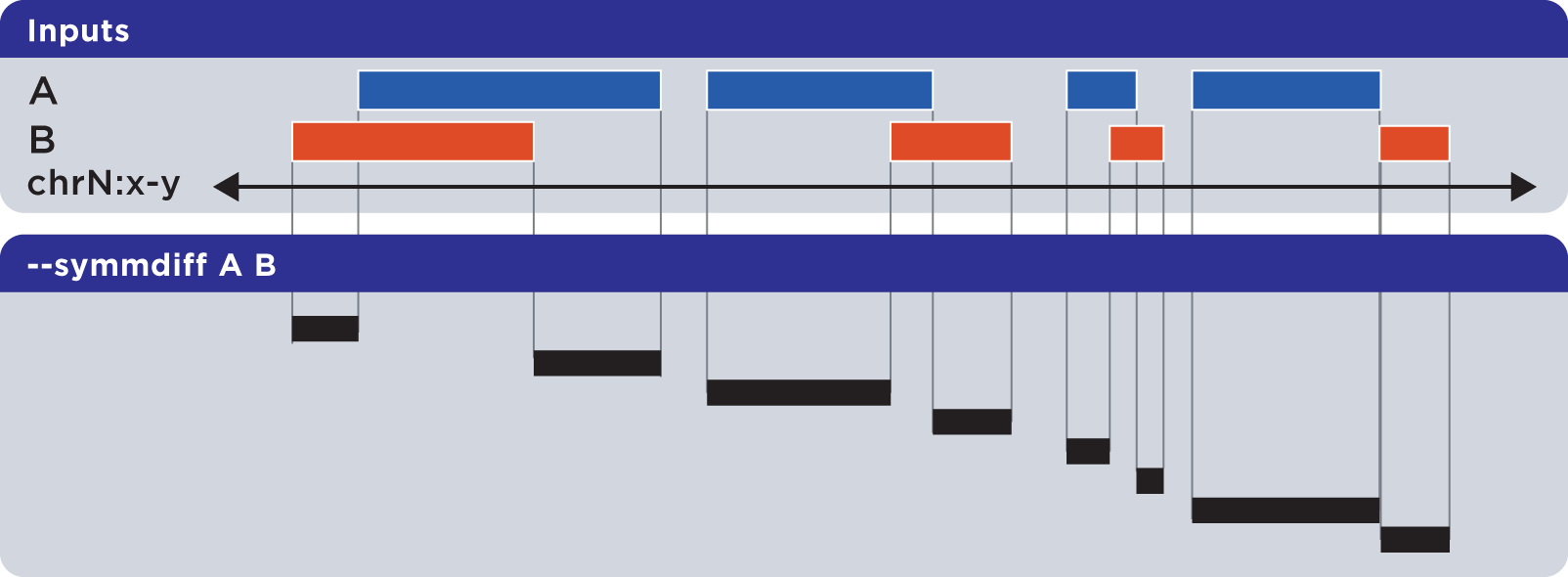
Example
To demonstrate --symmdiff, we use sorted sets First.bed and Second.bed and compute the genomic space that is unique to First and Second:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --symmdiff First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 120
chr1 125 150
chr1 160 300
chr1 400 460
chr1 470 475
chr1 490 550
Tip
It has been observed that --symmdiff (-s) is the same as the union of --difference A B with --difference B A, but --symmdiff runs faster in practice.
6.1.1.3.7. Intersect (-i, –intersect)¶
The --intersect operation determines genomic regions common to all input sets:

Example
To demonstrate --intersect, we use sorted sets First.bed and Second.bed and compute the genomic space that is common to both First and Second:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --intersect First.bed Second.bed > Result.bed
$ more Result.bed
chr1 120 125
chr1 150 160
chr1 460 470
Notice how this computed result is quite different from that of --element-of N, which functions more like a LEFT JOIN operation in SQL.
6.1.1.3.8. Merge (-m, –merge)¶
The --merge operation flattens all disjoint, overlapping, and adjoining element regions into contiguous, disjoint regions:
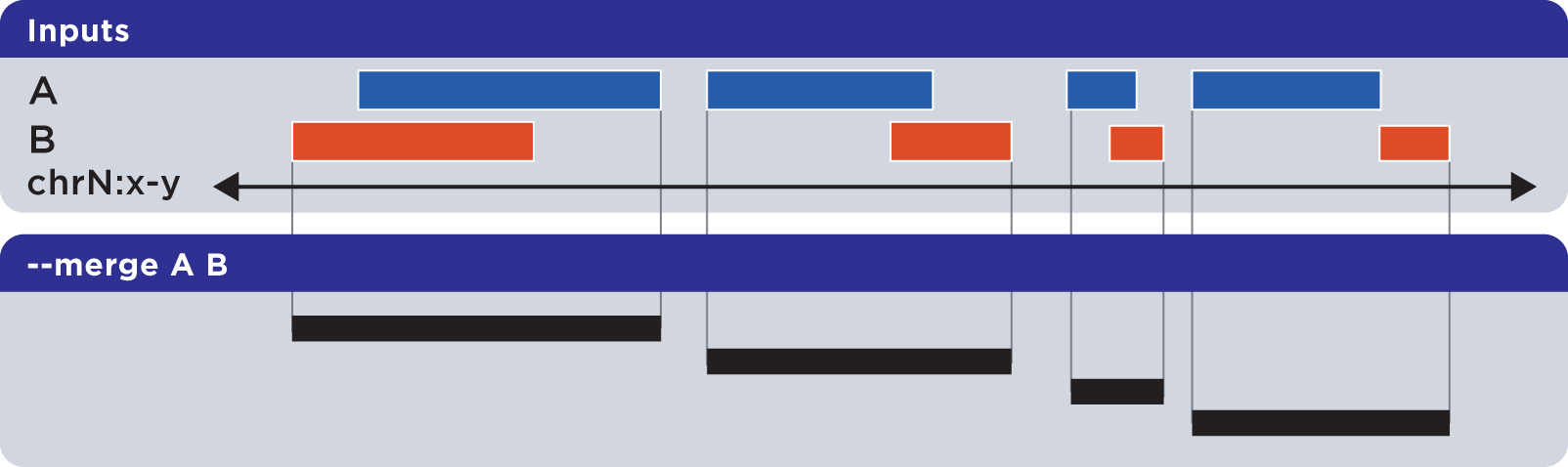
Example
To demonstrate --merge, we use sorted sets First.bed and Second.bed and compute the contiguous genomic space across both First and Second:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --merge First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 300
chr1 400 475
chr1 490 550
Tip
The preceding example shows use of --merge (-m) with two inputs, but the merge operation works just as well with one input, collapsing elements within the file that overlap or which are directly adjoining.
6.1.1.3.9. Partition (-p, –partition)¶
The --partition operator splits all overlapping input regions into a set of disjoint segments. One or more input files may be provided; this option will segment regions from all inputs:
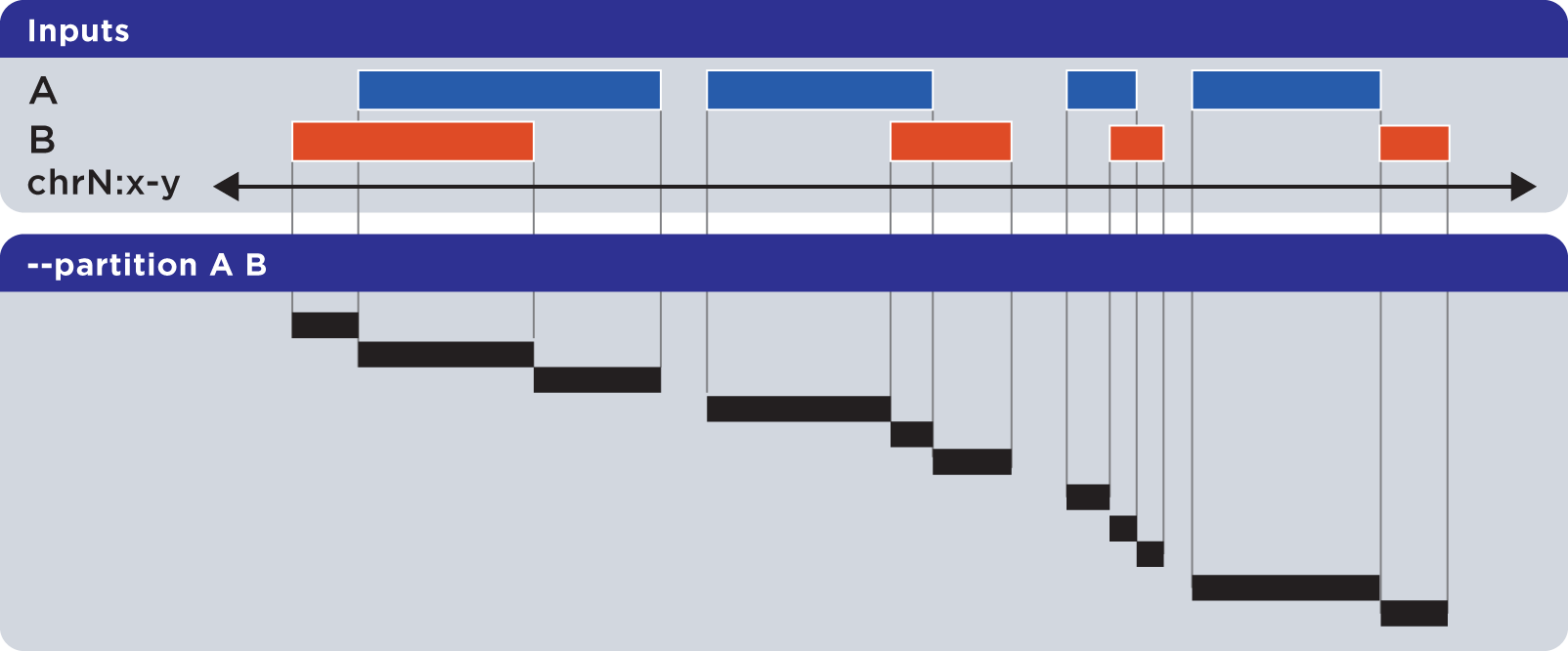
Example
To demonstrate --partition, we use sorted sets First.bed and Second.bed and compute disjointed genomic regions across both First and Second:
$ more First.bed
chr1 100 200
chr1 150 160
chr1 200 300
chr1 400 475
chr1 500 550
$ more Second.bed
chr1 120 125
chr1 150 155
chr1 150 160
chr1 460 470
chr1 490 500
$ bedops --partition First.bed Second.bed > Result.bed
$ more Result.bed
chr1 100 120
chr1 120 125
chr1 125 150
chr1 150 155
chr1 155 160
chr1 160 200
chr1 200 300
chr1 400 460
chr1 460 470
chr1 470 475
chr1 490 500
chr1 500 550
Notice that the result set of partitioned elements excludes any duplicates from input regions, thus enforcing the disjoint nature of the computed result.
Note
As with --merge, --complement and other “computing” operations, note the lack of ID, score and other columnar data in this computed result.
6.1.1.3.10. Chop (-w, –chop)¶
The --chop operator merges all overlapping input regions and “chops” them up into a set of disjoint segments of identical length (with a default of one base). One or more input files may be provided; this option will segment regions from all inputs:
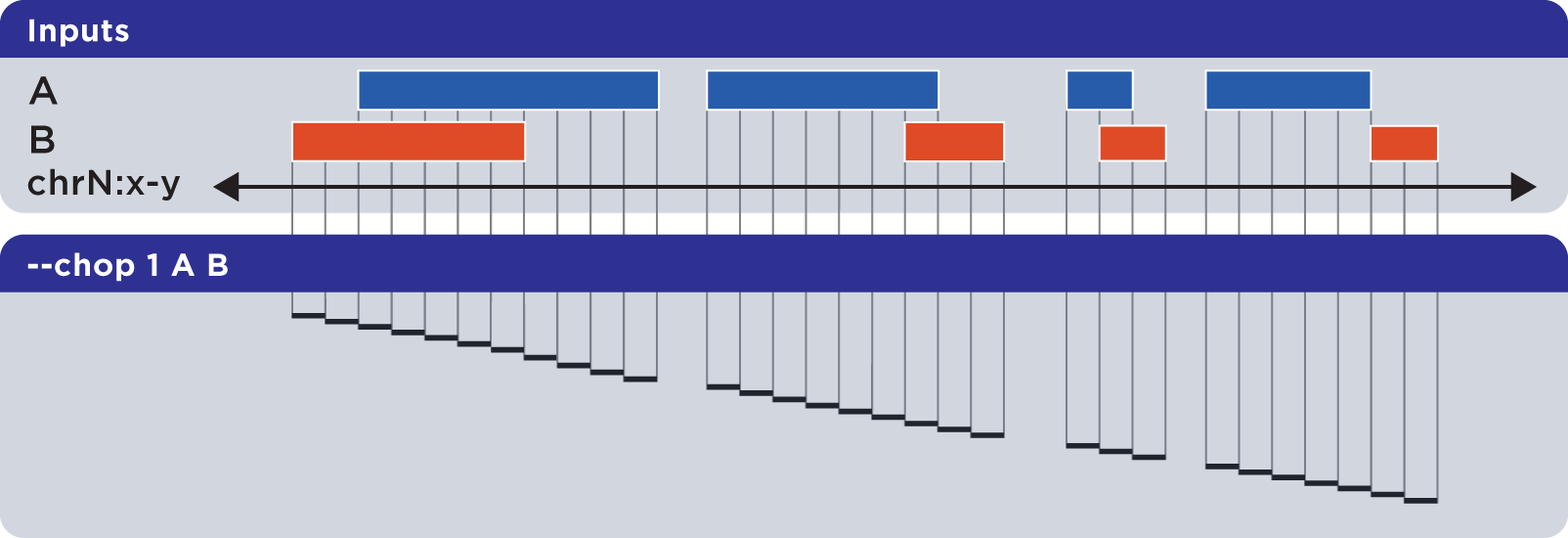
Example
To demonstrate --chop, we use a sorted set called Regions.bed and compute a set of one-base genomic regions constructed from the merged input elements:
$ more Regions.bed
chr1 100 105
chr1 120 127
chr1 122 124
$ bedops --chop 1 Regions.bed > Result.bed
$ more Result.bed
chr1 100 101
chr1 101 102
chr1 102 103
chr1 103 104
chr1 104 105
chr1 120 121
chr1 121 122
chr1 122 123
chr1 123 124
chr1 124 125
chr1 125 126
chr1 126 127
Note
Overlapping and nested regions are merged into contiguous ranges before chopping. The end result contains unique, non-overlapping elements.
6.1.1.3.11. Stagger (–stagger)¶
The --stagger operator works in conjunction with –chop. While --chop sets the size of each cut, the --stagger operator moves the start position of each cut by the specified number of bases, across each merged interval.
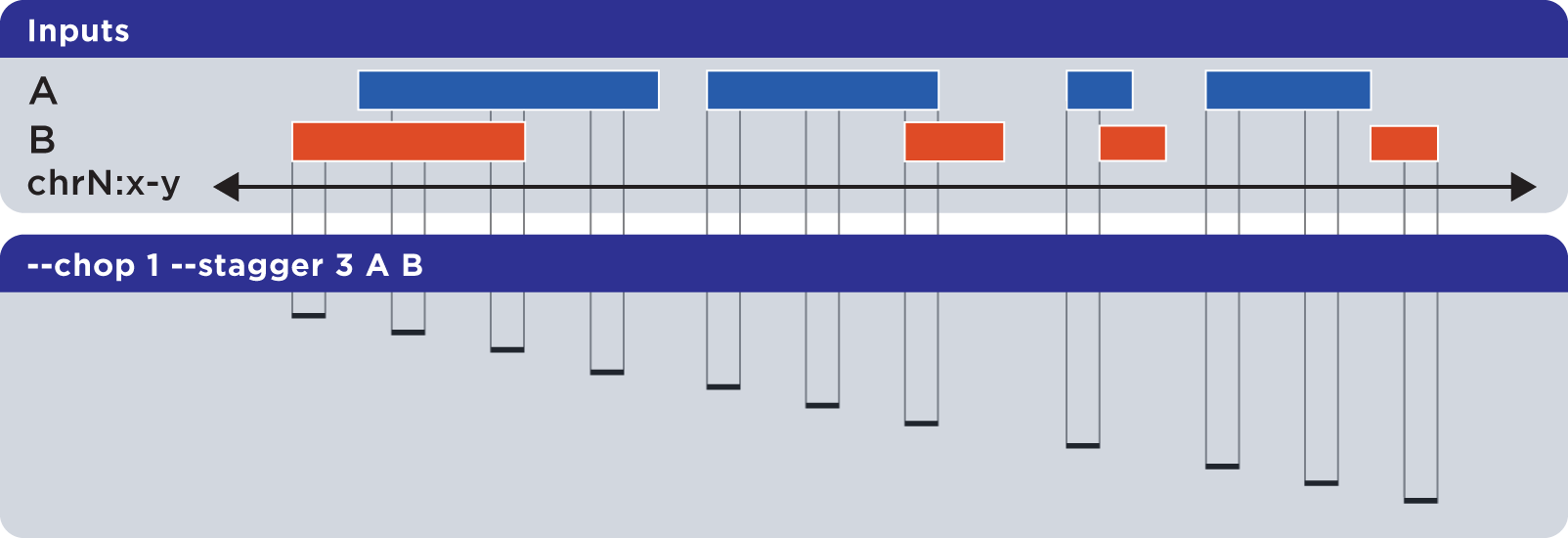
Example
To demonstrate --stagger, we use a sorted set called Regions.bed and compute a set of one-base genomic regions constructed from the merged input elements, but move the start position across the merged regions by three bases, before generating the next chop:
$ more Regions.bed
chr1 100 105
chr1 120 127
chr1 122 124
$ bedops --chop 1 --stagger 3 Regions.bed > Result.bed
$ more Result.bed
chr1 100 101
chr1 103 104
chr1 120 121
chr1 123 124
chr1 126 127
Note
Overlapping and nested regions are merged into contiguous ranges before chopping and staggering. The end result contains unique, non-overlapping elements.
6.1.1.3.12. Exclude (-x)¶
Like --stagger, -x is a sub-option of the –chop operator, and it may be used with or without --stagger. This option will remove any remainder genomic chunk that is smaller than that specified with --chop. For example, if you start with a 10 nt region and use --chop 4, the final segment would be 2 nt in length if -x is not specified. With -x, that last segment does not go to output. With -x, the chop operation produces output regions that are all the same size.
6.1.1.3.13. Per-chromosome operations (–chrom)¶
All operations on inputs can be restricted to one chromosome, by adding the --chrom <val> operator.
Note
This operator is highly useful for parallelization, where operations on large BED inputs can be split up by chromosome and pushed to separate nodes on a computational cluster. See the Efficiently creating Starch-formatted archives with a cluster documentation for a demonstration of this technique in action.
Example
To demonstrate the use of --chrom to restrict operations to a chromosome (such as chr3), we perform a per-chromosome union of elements from three sorted sets First.bed, Second.bed and Third.bed, each with elements from multiple chromosomes:
$ more First.bed
chr1 100 200
chr2 150 300
chr2 200 250
chr3 100 150
$ more Second.bed
chr2 50 150
chr2 400 600
$ more Third.bed
chr3 150 350
$ bedops --chrom chr3 --everything First.bed Second.bed Third.bed > Result.bed
$ more Result.bed
chr3 100 150
chr3 150 350
6.1.1.3.14. Range (–range)¶
The --range operation works in conjunction with other operations.
When used with one value (--range S), this operation symmetrically pads all elements of input sets by the specified integral value S. When the specified value is positive, every genomic segment grows in size. An element will grow asymmetrically to prevent growth beyond base position 0, if needed. Otherwise, when negative, elements shrink, and any element with zero (or less) length is discarded.
Alternatively, when used with two values (--range L:R), this operation asymmetrically pads elements, adding L to each start coordinate, and adding R to each stop coordinate. Negative values may be specified to grow or shrink the region, accordingly.
This option is immediately useful for adjusting the coordinate index of BED files. For example, to shift from 1-based to 0-based coordinate indexing:
$ bedops --range -1:-1 --everything my1BasedCoordinates.bed > my0BasedCoordinates.bed
And, likewise, for 0-based to 1-based indexing:
$ bedops --range 1:1 --everything my0BasedCoordinates.bed > my1BasedCoordinates.bed
Note
The --range value is applied to inputs prior to the application of other operations (such as --intersect or --merge, etc.).
Padding elements with bedops is much more efficient that doing so with awk or some other script, and you do not need to go back and resort your data. Even symmetric padding can cause data to become unsorted in non-obvious ways. Using --range ensures that your data remain sorted and it works efficiently with any set operation.
Also, note that the --element-of and --not-element-of operations behave differently with --range, in that only the second and subsequent input files are padded.
6.1.1.4. Starch support¶
The bedops application supports use of Starch-formatted archives as inputs, as well as text-based BED data. One or multiple inputs may be Starch archives.
Tip
By combining the --chrom operator with operations on Starch archives, the end user can achieve improved computing performance and disk space savings, particularly where bedops, bedmap and closest-features operations are applied with a computational cluster on separate chromosomes.
6.1.1.5. Error checking (–ec)¶
Use the --ec option in conjunction with any aforementioned operation to do more stringent checking of the inputs’ compliance to bedops requirements, including sorting checks, delimiter checks, among others.
To demonstrate, we can deliberately introduce a typo in dataset A, using the --ec option to try to catch it:
$ bedops --ec --everything BEDFileA
May use bedops --help for more help.
Error: in BEDFileA
First column should not have spaces. Consider 'chr1' vs. 'chr1 '. These are different names.
See row: 3
The typo introduced was the addition of a space within the third line of dataset A.
Note
Use of the --ec option will roughly double the running times of set operations, but it provides stringent error checking to ensure inputs and outputs are valid. --ec can help check problematic input and offers helpful hints for any needed corrections, when problems are detected.
6.1.1.6. Tips¶
6.1.1.6.1. Chaining operations¶
You can efficiently chain operations together, e.g.:
$ bedops --range 50 --merge A | bedops --intersect - B > answer.bed
In this example, elements from A are padded 50 bases up- and downstream and merged, before intersecting with coordinates in B.
6.1.1.6.2. Sorting inputs¶
For unsorted input, be sure to first use sort-bed to presort the data stream before using with bedops. Unsorted input will not work properly with BEDOPS tools.
Tip
If you will use an initially-unsorted file more than once, save the results of sorting. You only need to sort once! BEDOPS tools take in and export sorted data.